Table of Contents
Improvements
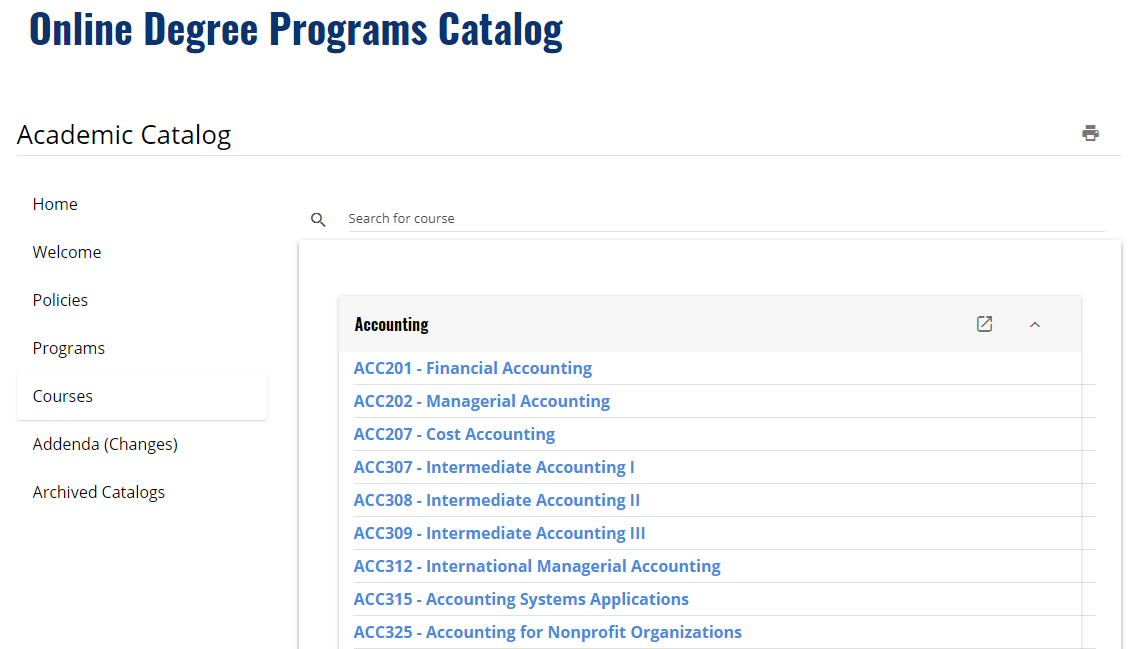
The goal was to implement the SNHU Course Catalog into the Slack bot so that users could query course data without leaving the program. This data is freely available on the SNHU Web Site (Online Degree Programs Catalog, 2018), but the challenge was extracting it into usable form for the Slack bot. Normally I would use the Beautiful Soup library to scrape web pages, but the SNHU Catalog appears to be a dynamic application that only loads the data as it needs to. Because of this, I needed to use Selenium to load a web driver and automate user browsing to scrape the data needed. This was a fun experience as I’ve never worked with Selenium before, and it was a necessary step to bring this feature to the bot. The process itself could be considered an algorithm of sorts, though not a very efficient one. It could be improved greatly by implementing some multithreaded processes, but for now I’m just happy it works.
Now that I have the data, I need to store and process it. For persistent storage, I am outputting the JSON catalog data in a file. I would like to migrate this to a Mongo database soon, but for now the file will do. The catalog is, essentially, associative data, structured of keys and values, much the same as a dictionary or phone book would be organized. In our data we have overarching subjects like “Accounting” and “Computer Science”, within each of these a series of courses such as “ACC201” or “CS200”, and then a series of encapsulated data like the course title, description, and how many credits the course is worth. An example of the data structure has been provided below.
{
"Accounting": {
"ACC201": {
"title": "Financial Accounting",
"description": "Financial Accounting ...",
"credits": "3"
}
}
...
}, {
"Computer Science": {
"CS200": {
"title": "Computer Science's Role in Industry",
"description": "This course introduces the role of ...",
"credits": "3"
}
}
...
}
Where the data is associative, it’s an easy fit for the Hash Table data structure. Both JSON data and the Python dict type are implementations of Hash Tables. While it’s likely that I will end us using the Python implementation in my own program, I thought I would try to implement my own data structure for this use case. Drawing on inspiration from the Hash Table implementation I completed for CS260, I ported much of that C++ code to Python. The Hash Table uses string values for the key, which it hashes by calculating the key values of all the characters and performs a modulo against the size of the table. This allows for O(1) time to access the data when searching by the key, because the same hashing function is used for inserting and retrieving data. With such a simple hashing function, there is the chance for collisions to occur, when two string keys hash to the same integer value. To address this, I used the same chaining technique used in CS260, so if two match the second value will be inserted at the end of a list at the hashed index slot. If we have lots of collisions, the retrieval of data will be slowed because the list structure used must be traversed to retrieve the matching key, at a time complexity of O(n) where n is the number of items to be checked before a match is found.
class HashItem:
def __init__(self, key, value):
self.key = key
self.value = value
from HashItem import HashItem
class HashTable:
def __init__(self, size=1000):
self.size = size
self.count = 0
self.items = 0
self.slots = [None for _ in range(self.size)]
self._keys = []
def _hash(self, key) -> int:
return sum([ord(c) for c in key]) % self.size
def keys(self):
return self._keys
def put(self, key, value):
item = HashItem(key, value)
index = self._hash(key)
if self.slots[index]:
self.slots[index].append(item)
self.count += 1
else:
self.slots[index] = [item]
self.items += 1
self._keys.append(key)
def get(self, key):
index = self._hash(key)
if self.slots[index]:
for item in self.slots[index]:
if item.key == key:
return item.value
return None
Once I had the Hash Table complete, I loaded the data from the JSON file into it, and then performed simple queries to test it against the Python dict implementation. Surprisingly, the two implementations performed nearly identically, but I would have to give the win to the Python dict because it has additional features that I have not implemented into the Hash Table. Because the structure of the catalog is a series of nested Hash Tables, I need to implement a wrapper class that will allow for easier access to different search features. I have only started these classes but should complete them as I implement the feature in to Noob SNHUbot. A great benefit of the wrapper classes will be that I can implement either the Hash Table or the dict and the access features will be abstracted away from the user.
Reflection
The biggest challenge I faced this week was time. My schedule was a little more full than usual, so I couldn’t give this enhancement as much time as it deserved. I am incredibly happy with what I was able to accomplish, completing the scraping tool to get the data I wanted to work with was the most challenging task. It was very rewarding to review data structures at a fundamental level, since I haven’t done much with them since CS260. Working in a higher-level language like Python abstracts a lot of the underlying data structures, so I haven’t had to think about them much. It was great to take many of the key parts of the Hash Table implementation from CS260 and port it to Python. I left out several things that I didn’t need right away, such as deletion and retrieving all records, but I will need to implement these to get the full functionality working. For this week, I only needed to implement a data structure that I could work and act as a proof of concept. The final details will be completed as they get implemented into the project. Though I wish I were further along with this enhancement, I believe the week was a successful one, and will be a great addition to the final product.