Today I implemented a new command into Noob SNHUbot that leverages the SNHU Course Catalog data previously scraped from the SNHU web site using Selenium. You can read the original article detailing the scraping process, as well as my efforts to create a Hash Table data structure implementation here.
Previously I had scraped the data and stored it in a text file in a format I thought I could import into MongoDB. Unfortunately, my formatting wasn’t correct, so I had to make a few modifications to snhu_scrape.py to output in the correct format. I also took this time to scrape more data from the page, including course requisites, which I was not doing prevously.
{"title": "Computer Science", "courses": [{"id": "CS200", "title": "Computer Science's Role in Industry", "description": "This course introduces the role of computer software in a variety of industries. Principles of hardware, software, computation, and algorithm development are introduced. Students learn the fundamentals of basic programming concepts including data types, variables, control structures, logical expressions, and arrays.", "credits": "3", "requisites": null}, {"id": "CS250", "title": "Software Development Lifecycle", "description": "Effective methodologies and models are necessary for developing high quality software. In this course, students learn how to identify and apply appropriate software development lifecycle models and methodologies. All phases of activity within the lifecycle, including analysis, design, development, and testing, are explored with an emphasis on the roles of the contributors within each phase. Software development methodologies are examined with a focus on the application of agile processes.", "credits": "3", "requisites": "Complete: \nIT145 - Foundation in Application Development (3)\nCS200 - Computer Science's Role in Industry (3)"}, ...]}
With the new data in the correct format it was a simple matter of using the mongoimport tool to import the data into a database and collection. For future improvements I may just log to data straight to the MongoDB instance, but for now it only adds a few extra steps that are easy enough to manage.
With the data in place, it was time to create the new command module, cmds/snhu_catalog.py. The new command would utilize the Hash Table implementation I created and tested during the initial scraping efforts, so I included HashTable.py, HashItem.py, and the Catalog.py classes into the BotHelper module. I wanted the Catalog and Course classes available from the BotHelper module, but left the HashTable implementations out, only needing them for internal purposes, so I added the following line to the BotHelper init file:
from .Catalog import Catalog, Course
With a few other minor modifications to HashTable.py and HashItem.py, I was ready to begin importing data into my data structures for the new command.
# Check if we're running with a database connection
if DB_CONFIG:
# perform imports
from noob_snhubot import mongo, slack_client
bot_id = slack_client.api_call("auth.test")["user_id"]
# change to catalog/subjects context
mongo.use_db('catalog')
mongo.use_collection('subjects')
# get all documents
data = mongo.find_documents({})
# create Catalog using HashTable implementation
catalog = Catalog()
for subject in data:
course_data = HashTable(47)
for course in subject['courses']:
course_data[course['id']] = Course(course['title'], course['description'], course['credits'], course['requisites'])
catalog.subjects[subject['title']] = course_data
else:
disabled = True
To start, because I wanted to make the MongoDB feature optional (so as to not discourage other developers that might work on the project), I need to make sure the bot is running with the MongoDB connection. I perform a circular import from noob_snhubot.py checking the DB_CONFIG variable, which is set up when the config.yml file is loaded or None. So if we are running with MongoDB, we import mongo, change the database and context to what we need, and import all documents from the database into a Python dictionary. Then we parse the dict into the Catalog class structure, using the custom HashTable implementation. If we’re not running with MongoDB, we set the disabled variable which changes the command response later in the code. Somewhat surprisingly, this all worked extremely well and was very easy to drop in place based on my previous work.
The command features three different response types. The first is when a user passes the help keyword, which results in the bot simply displaying a basic help message to inform users of the command structure and options.

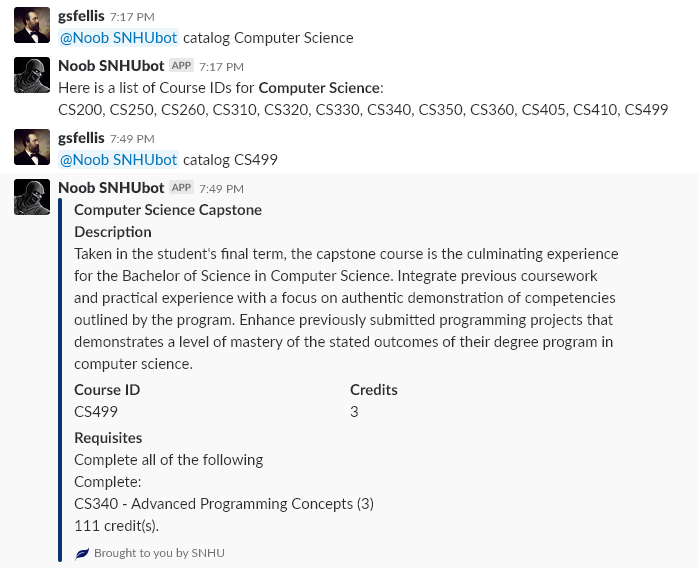
The second response can be seen in the top image and is when a user passes a particular subject to the catalog command, such as “Computer Science”, “Accounting”, or “Information Technology”. This method will take what the user passes in to it and search the Catalog.subjects.keys() for a match, performs a lookup to get the subject data from the data structure, then returns a comma separated list of the subject.keys().
# process subject
for key in catalog.subjects.keys():
if ' '.join(requests[1:]).title().startswith(key):
subject = catalog.get_subject(key)
response = "Here is a list of Course IDs for *{}*:\n{}".format(key, ', '.join(subject.keys()))
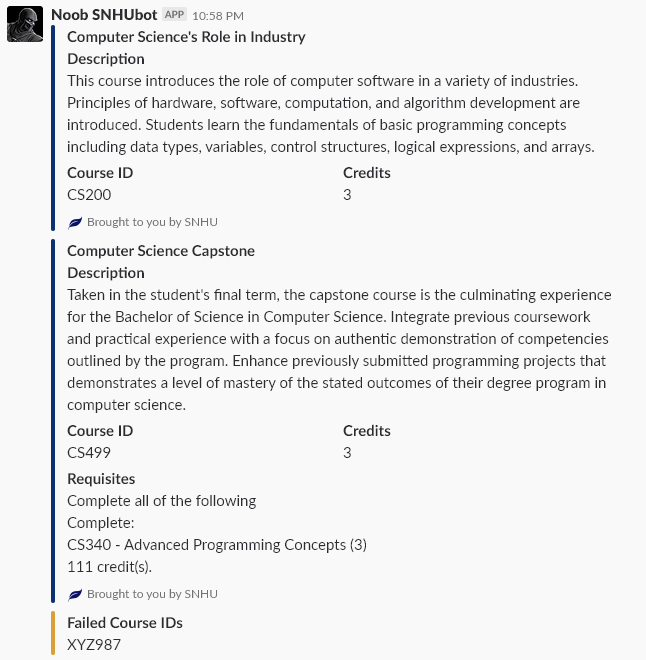
Easy enough. The final response is when a user passes in a specific Course ID to access the data about the course. They can feed a space delimited list of up to 3 courses to get the data for. I arbitrarily limited it to 3 just so users wouldn’t try flooding the bot by passing every course available.
I use a regex to express how the course ids should be presented, so they can be in the form of CS200 or CS-200 since both are common variations. So my if statement first checks for help, then it checks to see if the first argument matches the COURSE_FORMAT structure, and if it does it starts to process that. It creates a series of attachments based on the course data, or if the user passes bad course IDs, it will include those in a message. It’s very simple but effective logic.
COURSE_FORMAT = "^[a-zA-Z]{2,3}-?[0-9]{3}" # CS499, ACC-101, etc
requests = command.split()
if len(requests) > 1:
if requests[1].lower().startswith('help'):
## CODE OMITTED ##
elif re.match(COURSE_FORMAT, requests[1]):
# process course list
attachments = []
bad_courses = []
# get only 3 courses from list
for course in requests[1:4]:
course = course.upper()
match = re.match(COURSE_FORMAT, course)
if match is not None:
course = course.replace("-", "") # Strip the dash
course_data = catalog.get_course(course)
if course_data:
attach = {
## CODE OMITTED ##
}
if course_data.requisites:
## CODE OMITTED ##
attachments.append(attach)
else:
bad_courses.append(course)
All in all, I’m incredibly pleased with the successful implementation of this command. It came together very smoothly and functions incredibly fast. The data parsing only slowed the initial script startup by a few fractions of a second, but the bot responses are almost instantaneous because of the data structure implementation using Hash Tables. It’s incredibly efficient to lookup the keys used for subjects and courses, so I’m really happy with how this command turned out. It’s already been used a few times in the snhu_coders Slack community, and a request has been made for me to also implement the ability to get degree requirements. So if I student wanted to know what it takes to get a Computer Science degree, the bot would be able to inform them of the key classes, etc. This shouldn’t be difficult to implement, but it’ll be additional updates to the Selenium scraper, a new collection of data in the MongoDB database, and possibly a new data structure to represent the data.